计算(2)——GPU计算和大模型
前面提到,CPU运算的瓶颈往往不在于计算,而在于内存、存储和网络。相比于设计算法模型,CPU计算更侧重于工程。
相比下,GPU运算才是真正的高性能运算,虽然它的瓶颈同样可能来自GPU、显存、存储和网络,但提高计算能力、设计优秀的算法、编写高性能低开销的算子,是GPU运算的核心。GPU运算的典型场景就是大模型。
GPU 运算
前面提到,CPU 通过SIMD提供了向量化引擎,适用于OLAP存储和OLAP少量维度的数据分析。但如果是以下场景,就需要GPU了。
- 数据维度高,相比OLAP往往存储二维结构化数据,且列数较少;GPU处理的数据维度高(例如图片数据)、或者是非结构化数据(如自然语言序列)
- 需要高性能矩阵运算,如矩阵乘法、矩阵加法。
- 计算单元用有向无环图的形式组织,当前运算单元的输出是下一运算单元的输入,计算层很深,计算量庞大
- 指令数量和条件分支判断数量少
- 指令数量少意味着不用经常访问内存,cache数量少,无须多级cache。(GPU访问显存的频率远低于CPU访问cache的频率)
CUDA GPU并行编程模型
CUDA(Compute Unified Device Architecture)是NVIDIA为GPU设计的并行计算平台和编程模型。nvidia gpu物理上使用CUDA核心(FP32/INT32)执行浮点和整数运算, 每一个Cuda Core由1个浮点数单元FPU和1个逻辑运算单元ALU组成。除了cuda Core,nivida还用张量核Tensor Core模块用于执行融合乘法加法。
cuda的thread是最小计算单元, 用来处理单个数据。多个thread组成block,可用来执行矩阵处理。多个线程块的集合组成grid,用来表示一个大规模计算任务。cuda 引擎会调度thread/block/grid上的计算到合适的GPU硬件单元上执行。
向量加法的例子,用一个block执行向量加法
1 | // 向量加法核函数 |
pytorch 深度学习框架
PyTorch 是由 Facebook AI Research (FAIR) 开发的开源深度学习框架,以其 动态计算图、易用性 和 高效的 GPU 加速 著称,广泛应用于学术研究、工业界模型开发和部署。
python前端接口调用, 文档: https://pytorch.org/docs/stable/index.html
1 | import torch |
后端C++引擎libtorch, 可以直接基于libtorch进行C++开发。
- ATen 库:核心张量计算库,支持 CPU/GPU 统一代码。
- TorchScript:将 Python 模型转换为静态计算图(ScriptModule),用于高性能推理。
- CUDA 集成:通过 c10::cuda 实现低延迟 GPU 操作。
pytorch 可以很容易调用cuda开发的算子,参考 https://zhuanlan.zhihu.com/p/595851188
代码结构
1 | ├── ops |
src/sum_two_arrays/two_sum_cuda.cu
1 |
|
src/sum_two_arrays/two_sum.cpp
1 |
|
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) { m.def(“forward”, &two_sum_gpu …)} 表示
- pybind11 宏,声明一个 Python 模块,并创建模块对象
- 将 C++ 函数 two_sum_gpu 绑定到 Python 模块,并命名为 forward。
使用setup.py编译(也可以使用jit编译)
1 | from setuptools import find_packages, setup |
pytorch调用cuda算子
1 | # ops/ops_py/sum.py |
cudnn和nccl
cuDNN(CUDA Deep Neural Network Library)是英伟达推出的专为深度学习设计的GPU加速库。它针对深度神经网络中的核心操作(如卷积、池化、归一化等)提供高度优化的实现
1 | # 启动cudnn加速 |
NCCL(NVIDIA Collective Communications Library) 是 NVIDIA 开发的 GPU 专用通信库,旨在优化多 GPU 和多节点间的数据传输效率。cuDNN 可与 NCCL 结合实现多卡通信。
1 | model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank]) |
transformer和self-attention
以上讲了cpu适合通用计算,也就是cpu需要能够各种任务,包括进程任务,cache和内存读写,IO存储,需要具备中断处理能力,就像工作的人一样。CPU还提供了向量化指令增加向量数据处理的能力。GPU适合专门处理矩阵浮点型运算,这种矩阵浮点运算最显著的场景就是深度学习和大模型运算。
目前大模型基本是基于transformer和self-attention架构开发,相关分析 https://zhuanlan.zhihu.com/p/624740065 比较全面,我整理下总结
- 每个transformer层的参数量为12h^2,训练时每个参数占20字节,推理时每个参数占2个字节。h是隐藏层维度
- 每个参数前向计算需要2个浮点数运算(相当于一次乘法一次加法),反向需要4个浮点数运算(反向需要根据误差计算梯度,然后根据梯度更新权重,需要两次运算,计算量是前向计算的2倍)。一般采用激活重计算技术降低中间激活层的内存占用,这样子又需要一次前向计算。每个参数总计需要8个浮点数运算。推理时每个参数只要2个浮点数运算。
- 显存占用主要由1. 模型参数 2. 前向计算过程产生的中间激活 3. 后向计算得到的梯度 4.优化器状态四个方面组成。其中模型参数、后向计算得到的梯度、优化器状态参数之和只和隐藏层size有关,而前向计算过程产生的中间激活参数和batchsize、序列长度有关。可以通过减少batchsize,额外的激活重计算来降低中间激活参数。
1. 模型参数
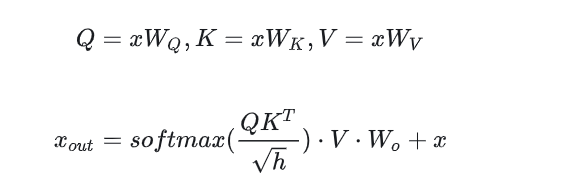
- transformer由l层组成,每层分为self-attention(多头注意力)和MLP两部分。self-attention块包含3个QKV权重矩阵和一个输出权重矩阵,每个矩阵维度[h, h], 加上偏置参数量为4h^2+4h, h为隐藏层维度
- MLP块由两个线性层组成,第一个线性层维度为[h, 4h], 第二个线性层维度为[4h, h], 加上偏置参数量为8h^2+5h
- self-attention块和MLP块之后各有一个layer norm层,包含两个参数,缩容参数alpha和偏置参数beta,2个layer norm参数量合计为4h
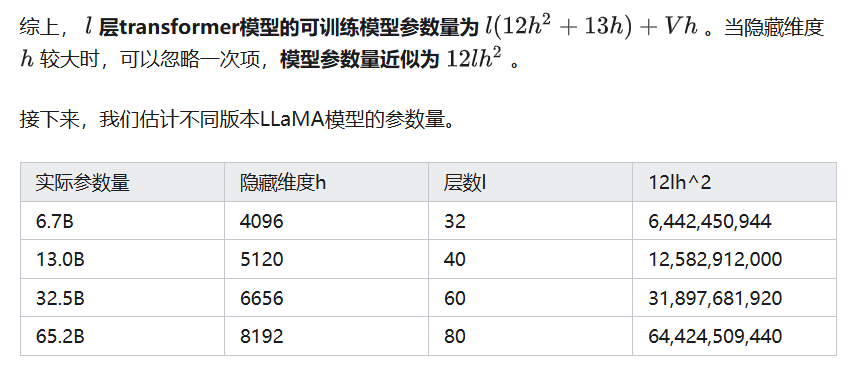
综上, 每个transformer层参数量为12h^2+13h, 对于l层transformer, 参数了近似为12lh^2
2. 参数显存分析
略
3. kvcache分析
加入kvcache后,一个典型的大模型生成式推断包含了两个阶段:
- 预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache和value cache(KV cache)。
- 解码阶段:使用并更新KV cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词。
kvcache 只影响第一步QKV矩阵的生成,将矩阵-矩阵乘法 降低为矩阵-向量乘法,减少参数量加速计算

KV Cache是Transformer推理性能优化的一项重要工程化技术,各大推理框架都已实现并将其进行了封装。可以看这篇文章 https://zhuanlan.zhihu.com/p/63083259
大模型加速
大模型加速,主要分为模型侧、计算侧和内存IO侧。模型侧主要是压缩和量化,计算侧包括并行计算,cuda算子优化以及MOE训练等,内存IO侧主要在内存分配,共享,高性能存储网络等。
1. 模型压缩
剪裁(Pruning), 核心思想是尽可能保证模型精度不受影响下减少网络的参数量,例如减少网络中神经元的数量
剪裁中常用的步骤1. 预训练大模型 2. 修剪网络, 训练小模型 3. 通过微调恢复剪裁对模型的损耗量化Quantization
量化的基本思想是将浮点计算替换成更低比特的计算,从而降低模型体积加快推理速度。量化可以采用定点近似(直接缩小位宽降低精度)和范围近似(通过统计学缩放映射浮点数,需要量化和反量化,精度较高)。知识蒸馏(Knowledge Distillation)
一种教师-学生的训练结构,通常是已训练好的教师模型提供知识,学生模型通过蒸馏训练来获取知识。将教师模型的输出作为软标签与学生模型的软预测计算蒸馏损失,将真实的硬标签与学生模型的硬预测计算学生损失,最终将两种损失结合训练学生模型
2. 计算侧加速
- 并行计算
数据并行(数据集拆分),流水线并行(模型拆分成子模型),张量并行(模型按层拆分),专家并行(MOE)
其中流水线并行是GPU内存不足的无奈之举,各层之间仍然是顺序执行的,并不能加速模型的运算。
张量并行可以使用nivida的Megatron库,将模型内部改为ColumnParallelLinear, ParallelMLP, ParallelAttention等结构
专家并行特指MOE训练(混和专家模型)
kvcache
加速KQV矩阵的生产运算cuda优化和算子融合
cuda 执行矩阵乘法,激活函数,softmax等,每个操作都对应一次cuda调用。可以自定义cuda Attention优化,以及将多个cuda算子融合到一起,减少cuda调用次数,提高性能。
内存和IO优化
FlashAttention
加速注意力计算并减少内存占用。FlashAttention的核心原理是通过将输入分块并在每个块上执行注意力操作,从而减少对高带宽内存(HBM)的读写操作。参考文章 https://zhuanlan.zhihu.com/p/676655352FlashDEcoding
FlashAttention对batch size和query length进行了并行化加速,Flash-Decoding在此基础上增加了一个新的并行化维度:keys/values的序列长度。即使batch size很小,但只要上下文足够长,它就可以充分利用GPU。Continuous Batching
一个批次中,某些请求可能会比其他请求提前“完成”,但这些完成的请求需要等待整个批次完成才释放资源。
Continuous Batching 不会等待批次中的每个序列完成生成,而是实现迭代级调度,一旦批处理中的序列完成生成,就可以在其位置插入新序列,不必等待整个批次完成。 参考文章 https://github.com/PaddleJitLab/CUDATutorial/blob/develop/docs/13_continuous_batch/README.mdPagedAttention
现有的推理系统将 KV Cache 存储在连续的显存空间中,导致显存碎片浪费,以及显存无法共享。
PagedAttention 将 KV cache 组织成了固定大小的 KV blocks,类似虚拟内存中的页。管理显存的分配,同时对推理的重复计算内存共享。
大模型推理框架
vLLM
vLLM 是一个快速、易于使用的 LLM 推理和服务库。可以接收流式的处理请求,并调度GPU和模型执行推理和输出
- 调度器
在每1个推理阶段,决定要把哪些数据送给模型做推理,同时负责给这些模型分配KV Cache物理块。 - Worker
CacheEngine:负责管控gpu/cpu上的KV cache物理块(调度器的block manager只负责物理块id的分配)
Worker.model:负责加载模型,并执行推理。
https://zhuanlan.zhihu.com/p/691045737
TensorRT
TensorRT 是 NVIDIA 推出的 高性能深度学习推理优化器,相比vLLM主要从调度层和计算/内存资源分配层做优化,TensorRT 主要在cuda和硬件层进行优化。
- 层融合(Layer Fusion):合并卷积、激活、归一化等连续操作为单一内核,减少内存访问开销。
- INT8:通过量化感知训练或校准集动态量化,速度提升 2-4 倍。
- Dynamic Tensor Memory 在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
- Multi stream execution 使用CUDA中的stream技术,最大化实现并行操作。
MOE训练
混合专家模型(Mixture of Experts, MOE)训练 是一种通过动态路由机制将输入分配给多个子网络(专家)的高效模型架构,在大规模模型中广泛应用
- 专家网络, 多个独立的子模型(如全连接层、Transformer块),每个专家专注不同特征模式。可以实现并行处理
- 门控网络(Gating) 根据输入生成权重,决定各专家的贡献比例(稀疏或软选择)
- 路由策略 控制输入如何分配给专家(如 Top-K 选择、负载均衡约束)。
优势
- 模型容量扩展,混和专家模型每次只计算局部的参数(激活局部的专家),因此能在GPU有限情况下训练大量参数的模型。增加专家数量可提升模型能力,而计算量仅随激活的专家数增长。
- 稀疏计算:仅部分专家参与推理(如 K=2),适合资源受限场景(如 GPU 显存优化)。
- 多模态学习:不同专家可处理不同类型输入(文本、图像等)。
参考文章,https://huggingface.co/blog/moe
deepseek开源
1. FlashMLA
deepseek 借鉴了FlashAttention项目中的一些理念,针对MLA进行优化的CUDA内核算子,并可集成到pytorch
链接 https://github.com/deepseek-ai/FlashMLA
文档, https://github.com/deepseek-ai/FlashMLA/blob/main/docs/20250422-new-kernel-deep-dive.md
2. DeepEP
DeepEP 是一个专门为混合专家(MoE)模型和专家并行(EP)设计的通信库。DeepEP is a communication library tailored for Mixture-of-Experts (MoE) and expert parallelism (EP). It provides high-throughput and low-latency all-to-all GPU kernels, which are also as known as MoE dispatch and combine. The library also supports low-precision operations, including FP8.
链接 https://github.com/deepseek-ai/DeepEP
3. DeepGEMM
通用矩阵乘法算子
4. DualPipe & EPLB
DualPipe 训练时流水线调度,采用了一种独特的调度策略,使得前向传播和反向传播可以在不同的GPU上同时进行
EPLB 实现专家负载均衡
5. 3FS
为大模型推理提供数据集和模型读写能力,主要关注小IO和大IO读,以及大IO写。
总结
CPU运算的适用于逻辑运算(如数据清洗),简单整数和向量计算(例如OLAP),而GPU运算适用于矩阵运算(如卷积、矩阵乘法等)。一般的计算模型是GPU-CUDA-Pytorch三件套。
大模型基于transformer构建,是基于多层矩阵运算的复杂模型。本文分析了transformer一层的参数量,计算量,显存使用量和kvcache、重计算加速等。注意大模型和传统流式处理(如Flink的区别)是,大模型是高度密集型矩阵运算,而Flink流式处理的运算并不复杂,侧重于数字或向量计算而非矩阵运算。但大模型推理后续替代Flink犹未可知。
对于大模型加速,主要分为模型侧、计算侧和内存IO侧。模型侧主要是压缩和量化,计算侧包括并行计算,cuda算子优化以及MOE训练等,内存IO侧主要在内存分配,共享,高性能存储网络等。
大模型推理框架,vLLM是一套推理工程的解决方案。最后deepseek开源了包括矩阵运算、MLP算子、高性能网络、MOE训练负责均衡以及高性能存储的项目,都很值得学习。
可以把GPU训练看到类似IO存储,以后的业务层
- 接收网络请求,准备执行环境
- 执行顺序和if-else逻辑,包括鉴权、流控、日志等
- 执行IO存储逻辑,包括写数据库/写文件/写缓存/写oss等
- 执行在线大数据处理逻辑,例如搜广推等(CPU计算)
- 执行大模型GPU推理逻辑,推理生成序列或预测结果
- 获得3,4,5的结果,返回给客户端
业务层本身是无状态的CPU计算,主要关注的
- 接收海量请求,也就是高并发
- 自身可以水平扩展
- 明确后台的能力,为数据库层,模型推理层提供缓存,流控,队列等,防止后端压力过大
- 复杂的业务逻辑解耦
IO存储、在线大数据处理、大模型推理层负责提供高并发、高性能的存储和计算推理服务。
by the way, 显然实时性的业务更具有挑战性,需要低延迟、高吞吐和高QOS。例如后端业务层开发(毫无疑问要是实时返回的)、搜索广告推荐(需要实时数据分析)、大模型推理(需要实时推理)、分布式数据库和存储(需要提供实时表和文件读写服务)、量化交易(需要低延迟自动化和手段触发策略)等。如果某业务无实时性处理要求,那技术性将会大打折扣。
本文标题:计算(2)——GPU计算和大模型
文章作者:Infinity
发布时间:2025-05-03
最后更新:2025-06-02
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!