计算(1)——CPU计算和大数据
由于本人是存储方向,前面的文章大多数是关于存储的。计算机系统=计算+存储,其中计算包括计算单元(CPU、GPU)、cacheline和内存态的处理, 而存储特指IO处理。计算可分为CPU计算和GPU计算两部分,前者的典型场景是操作系统处理、进程执行、互联网业务处理和大数据和OLAP处理等。后者的典型场景是大模型的训练推理。
本文介绍CPU计算。CPU计算主要包括业务处理和大数据处理两部分,CPU运算的瓶颈往往不在于计算,而在于内存、存储和网络(可能这是ddia 把大数据计算也放到内的原因)。相比于算法模型,CPU计算更侧重于工程。
CPU的计算
流水线和分支预测、指令重排序
假设系统只有一个进程运行,进程文件首先被装载到内存。CPU执行的过程大致是:取指(Fetch, 载入指令存入指令寄存器)、解码(Decode,将指令解码)、执行(Execute,执行指令)、访存(Memory Access,执行指令期间可能需要访问内存)和写回(Write Back,将指令执行结果写回内存)。常见的指令有
- x = 1, 赋值指令,只需要读存、写存
- x = x + 1, 加法指令,需要读存、加法、写存
- if (x), 条件判断指令,需要读存、比较、更新指令寄存器(记录下一个执行的指令)
假设一个进程有4条指令,执行每个指令都需要取值、解码、执行、访存和写回五步。原始的执行方法每个指令都需要5个CPU周期,总共需要4*5=20个周期。其中取值、解码、访存和写回CPU都是空闲的,这时候的CPU利用率只有20%。
CPU可以采用pipeline(流水线)算法执行以上5条指令,因为取值、解码、访存和写回操作是不占CPU周期的,因此CPU可以在一个周期内完成第一条指令的执行、第二条指令的解码、第三条指令的访存,如图所示。这时候CPU完成4条指令只需要8个CPU周期,CPU利用率为50%。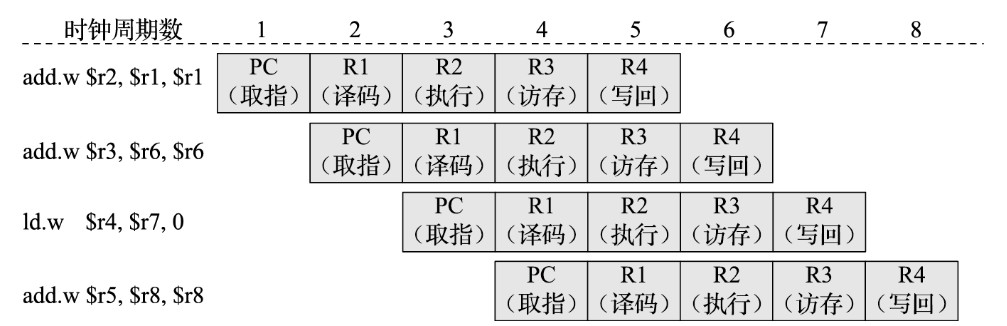
在流水线算法中,每个指令任务由链式的的子任务组成,有的子任务要操作(执行阶段),有的子任务则只需要看一眼(取指、解码、访存、写回操作),不占用CPU执行周期。摆在CPU面前的是若干并行的指令,CPU每个周期只执行一个任务需要操作的子任务,在多个任务并行的情况下,CPU每个周期都有活干,不会有周期空闲。
两个因素可能导致流水线暂停
- 条件判断指令
条件判断指令导致流水线暂停。由于下一条指令取决于条件判断指令的执行结果,CPU需要等待条件判断指令执行完,期间无法正常的流水线任务。(正常的流水线任务旧的指令不断结束,新的指令不断加入流水线,但执行条件判断指令相当于在它执行完之前,无新的指令加入流水线)。
处理手段是采用分支预测,CPU或编译期会预测条件指令true/false哪个概率更高,直接将概率高的指令加入流水线(相当于条件执行转为顺序执行),如果预测失败,流水线u回滚,重新执行分支后的指令。C/C++ 可以通过likely/unlikely 宏来提醒编译期概率高的条件。
- 指令间相互依赖
也就是指令1未完全执行完,指令2无法执行。如果有这样的依赖关系,CPU就不能通过子任务流水线方式运行指令1和2,而是必须等指令1执行完最后一步写回,才能执行指令2。
处理手段是指令重排序和乱序执行,若指令1,2执行有依赖,如果指令3不依赖1和2,CPU可以转而执行指令3。执行流变为1,3,2,1、3可以流水线并行,3、2也可以流水线并行。
CPU指令重排序可以保证单线程的排序前后的执行结果一致,但无法保证多线程一致(主要是可见性无法保证)。可以通过在程序中加内存屏障和内存序,保证两个指令之间不会重排序,且store-release指令的执行结果load-acquire指令一定可以看到。
CPU执行的计算
CPU的工作分为以下几种
- 寄存器赋值,访存等读写操作。为了提高访存效率(CPU获取指令会大量访存,访存会降低CPU使用率), CPU会引用三级cache。
- x >0 等bool 运算, 用于条件分支判断
- x+1, x*2等整数算数运算
- 3.4*5.6 等浮点数运算
- MMU 地址转换,MMU有TLB cache和转换单元组成。操作系统把MMU的输出到物理地址的映射记录到内存地址中,地址先通过MMU运算出结果,再根据结果从内存中找到物理地址。
- CPU硬中断(如缺页中断),转而去指定地址执行中断处理程序
- 时钟,记录CPU周期,作为心跳触发CPU循环执行指令
- 控制器/调度器,负责指令执行更精细化的控制和调度
CPU像真实的一个人,他的工作是循环执行指令,这些指令是串行发来的,需要调度器的思考进行分支预测、指令重排序等优化以便于流水线并行。同时随时会有其他的急事通过中断打断他。CPU更适合执行通用复杂的指令,应付各种场景,如果给他一个计算密集型任务,例如密码解密,CPU会很吃力。
相比之下GPU更像工厂的机器,专门执行特定任务,效率远高于CPU。CPU控制GPU如同现实中的人操纵机器。
将专用计算从CPU卸载是硬件相当重要的发展方向,如收发网络包由CPU处理网卡到DMA再到RDMA,浮点运算由CPU 到GPU等。
CPU的向量化计算
为了提高CPU的浮点和向量运算能力,英特尔引入了SIMD(Single Instruction, Multiple Data)指令集,SIMD指令集可以实现一条指令计算多个数据,如向量加法、向量乘法、向量比较、向量位运算等。
SIMD有专门的向量处理单元,SIMD寄存器一般很长,整个向量直接存到寄存器中,向量运算指令将向量数据从寄存器中取出,传入向量运算单元运算,将运算结果写入寄存器。
SIMD在IO层往往配合列式存储,执行分析运算时。程序首先从存储层读取少量列到内存,然后依靠SIMD指令对列进行向量化运算。列式存储还可以充分利用寄存器和cache的局部性,需要反复计算的向量不必经常访存。列式存储配合数据压缩,减少列式存储的size,尽可能将列数据放于缓存和内存中,减少IO和网络开销,提升性能。
ClickHouse 就是一个采用向量化引擎、列存储和列压缩的高性能分析性数据库。
增加CPU计算能力和虚拟化
稳定、性能、成本是分析一个系统的主要切入点,我们从这三个角度分析增加CPU处理能力的手段
- 多核CPU,通过多核并行能力提高CPU计算能力。与之而来的是操作系统的多进程/线程批处理,目的之一是为了提高CPU处理能力。
- 多线程的锁争抢会影响线程执行,线程的阻塞(如阻塞在锁或IO)也会降低CPU的有效利用率。另外由于分配线程需要资源,操作系统能够分配的线程有限。因此引入协程来增强处理能力,协程下层的线程不会阻塞,一般创建CPU核数的线程,线程之上创建大量协程,是计算侧提高CPU利用率的有效方案。
由于CPU的任务很复杂,不想GPU那样只有单一的矩阵浮点运算任务,因此CPU利用率往往比较波动。可能某时刻有大量请求进来,某时刻请求有比较少。这时候我们希望CPU的计算具有扩展能力。例如我们有一台96核12G的物理机,当请求量变多时,机器用来处理一个服务;当请求量年少时,这个机器可以处理其他服务。这样子这台物理机的CPU利用率会比较稳定。
计算侧扩展能力就要引入虚拟化,虚拟化的手段主要有两个,虚拟机和docker容器
- 虚拟机通过 Hypervisor(如 VMware、VirtualBox、KVM)在物理硬件上虚拟化完整的操作系统(Guest OS),每个 VM 独立运行,彼此隔离。虚拟机可以借助VT-x和virtio等技术减少虚拟化的开销。虚拟机的资源隔离性强,但耗费资源多、性能有损失、迁移能力较差,主要使用在云计算的云服务器,是计算和内存资源的包装,属于IASS层。
- 容器是操作系统内核提供的虚拟化技术,通过 cgroups 和 namespaces 实现资源隔离。容器相比虚拟机资源消耗低、性能高、迁移能力强,但物理机上的容器公用一个操作系统,资源可能相互影响。容器一般在物理机上以应用的形式运行,当容器资源不足,可以在线扩容容器的CPU和内存资源;若物理机资源不足,可动态将容器迁移至其他物理机。为了提高容器的调度能力,容器上的服务一般是无状态的,容器使用存储接口访问物理机或分布式文件系统的存储服务。
- 使用容器,降低了服务的计算成本,同时提高了服务的稳定性。一个容器挂了,备用容器会自动顶上来。容器集群中,负责容器调度的是master,而服务所在容器是worker。也就是说,容器集群中,我们的互联网服务,包括收发包、路由、鉴权、流控等,都是分布式计算。而用到的缓存、数据库和文件存储等,是分布式存储。
由于CPU的任务很复杂,因此CPU利用率往往比较波动,提升比较困难。需要全方面系统的分析。
大数据计算
大数据计算的3V问题
- Volume(数据量), PB级数据存储与处理(HDFS和S3)
- Velocity(速度): 实时/近实时计算(如Flink)。
- Variety(多样性): 结构化、半结构化、非结构化数据混合处理
数据的生命周期
- 数据获取,离线批处理需要从日志等复杂数据源中获取,而在线处理往往只需要从数据仓库获取关键数据,以提高实时性
- 如日志文件(描述系统的耗时、QPS、trace等),用户请求(请求携带了用户信息、请求参数、用户行为等),数据库和仓库(历史的用户行为,用户画像等)
- 用户数据是互联网公司的核心资产之一,互联网流量打的公司也具有更多有价值的数据,如阿里的电商数据、字节的视频数据、百度的搜索数据、腾讯的社交和游戏数据等
- 数据清洗,数据清洗也是一种大数据处理,往往用于批处理。如统一字段格式,删除重复数据,修正异常数据,对数据进行归一化等
- 数据模型处理
- 如果是离线批处理,数据模型处理往往比较简单,例如从用户请求中提取特征和预测标签,将整理好的数据写入到数据仓库。
- 如果是在线处理,要拿当前的输入数据和从数据仓库获得价值数据输入模型,结合业务场景(比如推荐、广告、搜索等),拿到TopN的结果(粗排+精排),返回给客户。这个过程需要准确、快速,也需要结合业务影响(例如广告竞价排名,广告推荐等)。
- 数据输出和存储。对于离线数据处理,数据会输出到数据仓库,对于在线数据处理,数据返回给客户端,或到下一层进一步处理。
离线数据处理更像是纯粹的分布式计算,而在线数据数据处理需要考虑多种因素,包括实时性、业务场景、准确性指标等。
OLAP和数据仓库
数据仓库存储的数据通常是结构化的,即按照事先定义好的格式和模式进行组织和存储,集成了来自多个不同来源的数据。
- 数据仓库中的数据是按照一定的主题域进行组织。主题是指用户使用数据仓库进行决策时所关心的重点方面。数据仓库的数据是用来分析的结构化数据(对应数据库的数据是主要用来处理用户请求,而非用于数据分析)。
OLAP(Online Analytical Processing),是一种分析型数据库,常作为数据仓库的存储引擎。适合OLAP的场景
- 数据以批量/流式顺序写入,插入和更新操作少。读取时不按照主键读取一行,而是直接读取一列
- 每个列代表维度,例如数据设计时间、区域、用户群等多维度
OLTP(Online Transaction Processing)OLTP通常按行(记录)存储,OLTP支持按主键读取一行,和更新数据等。OLAP表往往直接按照列读取用于分析,行数通常远大于列数(例如实时日志、用户实时特征数据等),往往以列的方式存储。
显然OLAP适合少量维度数据,每个维度大量数据的数据挖掘读取。OLAP是数据仓库的存储引擎,从数据源获取数据,进行数据清洗后,将数据写入到OLAP。OLAP支持数据挖掘模型按列读取数据进行分析处理(例如降维、预测等,会增加或减少维度),将数据处理结果写回到OLAP。
ETL 离线大数据处理流程
大数据的ETL(Extract, Transform, Load)模型 是数据从源系统到目标数据仓库或数据湖的核心流程
- 数据抽取(Extract),从数据库、文件、API等拉取数据,支持全量/增量同步
- 数据转换(Transform)清洗(去重、缺失值处理)、标准化(字段映射)、聚合计算
- 数据加载(Load)写入目标存储(数据仓库、数据湖),优化存储格式(列存/分区
例如,电商用户行为数据ETL
1. 抽取:从Nginx日志(JSON)和MySQL订单表增量拉取数据。
2. 转换:日志解析(提取user_id、event_time)。订单表与日志数据JOIN,生成用户行为宽表。
3. 加载:写入Hive分区表(按dt分区)供BI分析。
可以看到,离线大数据处理真正模型计算的部分比较简单,大致就是select检索,非结构化数据解析和清洗,维度聚合等,且计算模型往往是框架提供的。大多数的工作量在数据抽取、数据清洗上的计算、存储上的优化上。(相对比较无趣)
湖仓一体化,用数据湖(主要是S3)存储原始数据(结构化、半结构化、非结构化),数据仓库存储经过清洗、结构化处理的数据。模型的分析从数据仓库(OLAP)读取数据、处理、写回数据。
Flink 实时数据处理
在线数据处理的场景包括搜索、推荐、广告等,需要实时性,结果准确,同时需要结合业务。Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台, 本部门主要看流处理。
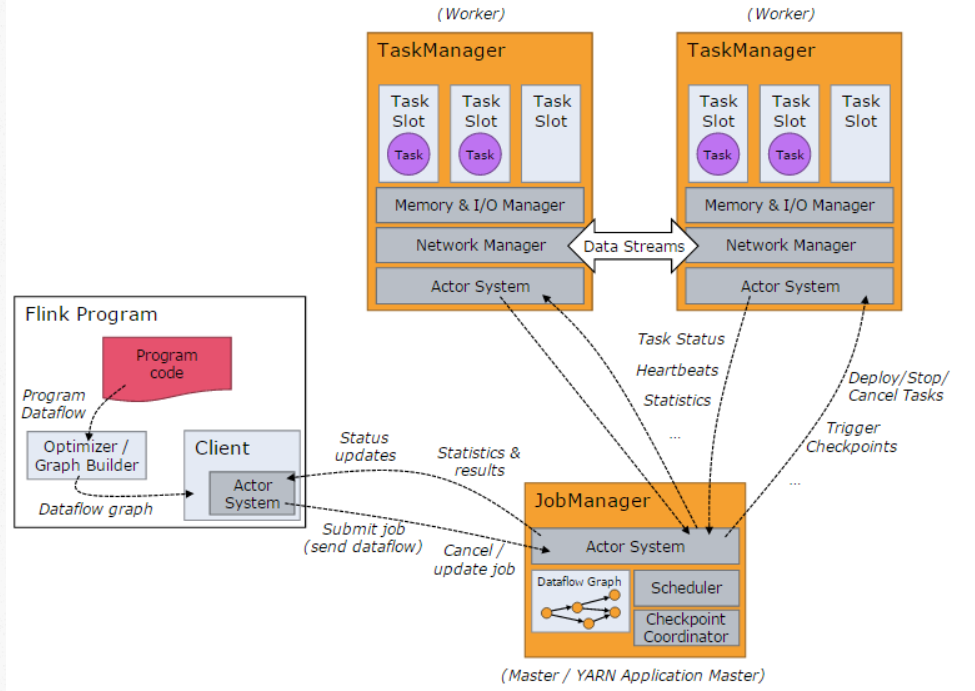
Flink的架构
- Flink支持通过producer-consumer模型接受需要处理的流数据,将流数据源做我datasource
- JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个子Task的执行。JobManager还负责收集Job的状态信息。
- TaskManager也是一个Actor,它是实际负责执行计算的Worker,负责执行Flink Job的Task。
- 每个task对应flink的一个算子,如map(…).setParallelism(2), 可并行执行
- Flink基于Checkpoint机制实现容错,它的原理是不断地生成分布式Streaming数据流Snapshot。在流处理失败时,通过这些Snapshot可以恢复数据流处理。
应用场景
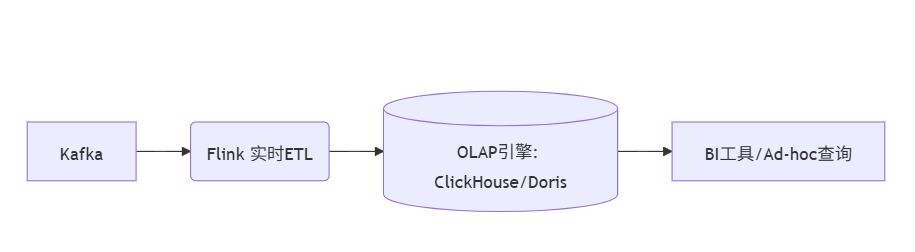
日志实时监控
例如队列接受数据源的日志数据,实时监控服务器日志、应用性能指标,触发异常告警(如错误率突增、服务宕机)。实时推荐系统
通过消息队列接受用户实时行为(点击、搜索),读取OLAP的用户画像,调用模型预测,将推荐结果返回给用户
基于CPU的大数据计算是低维向量运算,计算量并不大。大数据计算的瓶颈往往不在于计算,而在于内存/存储。相比于算法模型,大数据计算更侧重于工程。
本文标题:计算(1)——CPU计算和大数据
文章作者:Infinity
发布时间:2025-04-27
最后更新:2025-04-29
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!