存储——谈存储文件系统
文件系统是组织磁盘的形式, 文件系统提供了文件元数据信息,以及文件内容寻址能力(即将文件offset+length映射为磁盘位置);另一方面适配不同的磁盘硬件,让用户程序无须考虑硬件的区别。对用户程序来说,存储等于文件系统。
文件系统整体可以由客户端、元数据服务、数据服务三个部分组成, 包括read, write, setattr, getattr, lookup, readdir, create, rename, hardlink, symlink, readlink, remove等12个接口,支持随机读写文件。
为什么要有分布式文件系统? 1. 提供水平可扩展, 海量高性能存储 2. 提供多客户端的并发访问服务
对象存储系统和minIO
文件系统大致包括如下12个接口
- read, write读写文件
- setattr, getattr,读写文件属性(元数据)
- lookup,目录结构使用,根据父handle+文件名获得子文件handle
- readdir, 目录结构使用,获得目录中的文件名,相当于读目录
- create,创建文件
- rename,目录结构使用,将某文件从当前目录move到其他目录下
- hardlink,目录结构用,创建文件的硬链接(硬链接相当于文件具有两个path)
- symlink, readlink,目录结构用,创建和读软链接,基本等价于create和read
- remove,删除文件或空目录
最简单的是不支持目录的系统,也就是对象存储。对象存储的文件系统和文件分别称为bucket和object,object 完全平铺在bucket 根目录。
对象存储只支持read(getobject), write(putobject, appendobject), setattr(putobject), getattr(getobjectmeta),create(putobject), remove(remove object)
对象存储的写文件只支持append写,不支持随机写,不支持删除数据(truncate)
对象存储几乎是最简单的文件系统,我们可以看下对象存储简化操作后的好处
- 不支持目录,水平扩展简单。目录通过父目录-子目录的递归结构将文件系统组织成树的形式,目录树的水平扩展就需要按照目录树拆分,并且即使按照目录树划分,水平扩展也没有那么丝滑。对象存储水平扩展简单,一个object可以存在任意机器。这让oss的bucket 的object数量理论无上限,具有规模成本优势,可以随意建大规模object,无须担心性能退化。
- 文件read, write, create, remove等接口的调用也容易水平扩展,这让对象存储的IOPS极高。
- 只支持append写,容易加EC码降成本,性能不会受随机写和truncate的波动,性能稳定
对象存储容量和IOPS可水平扩展,性能高且稳定,十分适合作为数据的基础存储,例如ceph就使用对象存储作为块和文件存储的基础。
minIO是一个开源的对象存储,采用Golang语言实现。集群部署采用去中心化无共享架构,各节点间为对等关系,连接至任一节点均可实现对集群的访问。
- 一般的,客户端使用hash算法确定某个bucket和object name对应的erasure set 位置,object的数据和元数据指定存储在某erasure set。(每个erasure set包含一组硬盘,其数量通常为4至16块;EC的每一笔写会划分成若干段,例如8+3纠删码分成8段,同时生成3个校验块,最后11段数据每段独立写到不同磁盘,随机写不利于纠删码创建和优化)
- 如果后台增删节点导致object位置发生变化,后端服务器将请求路由到目标服务器,客户端更新位置信息。
- object数据和元数据在相同erasure set中存储,object之间shared-nothing(就是完全独立),容易水平扩展。object的数据和元数据都对应server指定磁盘文件系统的文件。
- 客户端使用https之上的s3协议。
minIO 旨在提供s3协议的对象存储服务,用来存储静态数据,并支持EC保证数据安全。但其并非作为存储底座,因此性能一般且没有太多性能优化。此外。listobject性能很差。
对象存储作为存储底座(可横向扩展、高性能、容错的分布式文件系统),可以参考ceph和lustre。
linux ext4文件系统
2008年发布
元数据由内存的inode 数据结构记录,inode 索引表,是个kv结构,key是inode号,value是对应的块位置。用来快速根据inode号找到inode结构在磁盘的位置。inode索引表常驻内存。每个inode 在内存中通过address_space(基数树)标志inode 使用的page 树。内存的page 会记录该page对应的磁盘块,从而调动磁盘读写数据。
linux/ext4 系统使用文件名 hash快速找到文件inode结构(通过dentry)
ext4用块为单位组织磁盘,块大小为4KB,块可以分为两类,元数据块用来存inode结构,对应内存的inode结构,数据库则用来存数据,对应内存的page。块使用bitmap标志块有无使用, 作用1. 快速分配新块来写数据,2. 快速定位块的位置
linux 使用 vfs 向实现不同的文件系统向用户程序提供提供一致的接口,vfs只支持posix语义的文件系统,也就是必须支持上述12个文件系统操作,以及支持文件随机读写和truncate操作。vfs支持的posix文件系统包括ext4, nfs, fuse等
ext4 文件系统的问题
- ext4文件系统不可跨磁盘存在,可扩展性有限
- ext4文件系统元数据和数据一起存放,未分离,但运行时文件元数据基本存放在内存中,元数据性能很强
Glusterfs
GlusterFS 文件系统,
- 存储服务器的Brick 是存储基本单位,Brick通过冗余性保证数据安全。Brick是一个目录。客户端根据 hash 算法定位到 Brick,找到Brick后进一步读写文件数据和元数据
- Brick是文件系统的一个目录,Brick本身是可以横向扩展的。Brick中的文件读写创建和内部目录的readdir 性能都比较高
- 但需要跨Brick的rename, ls性能比较差
- 客户端通过 FUSE 或 NFS/SMB 协议挂载 GlusterFS 卷,执行读写操作。客户端直接与存储节点通信,无需经过中心元数据服务器。
GlusterFS 相当于简单粗暴的直接按照目录拆分文件系统实现水平扩展,Brick目录内部的操作(包括子目录)性能很好,但ls, rename, link等需要跨Brick的操作性能较差。
文档, https://docs.gluster.org/en/main/Quick-Start-Guide/Architecture/#types-of-translators
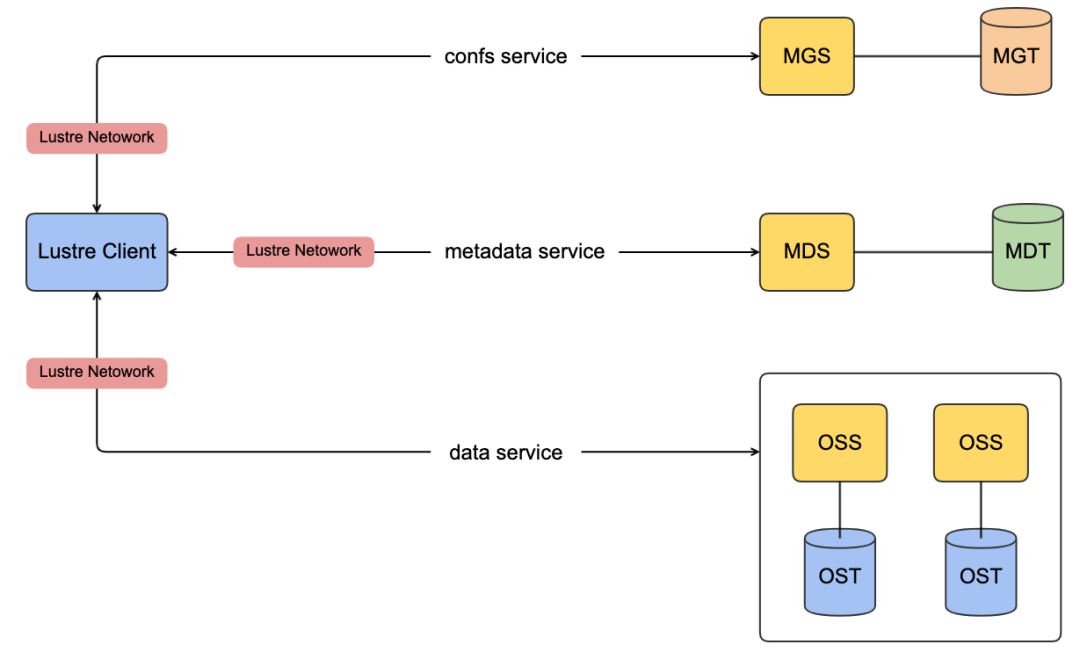
Lustre
Lustre 2003年发布, 底座为对象存储的分布式文件系统。由元数据服务(mds)、对象存储服务(oss)和客户端(client) 三个部分组成
mds,提供目录和元数据服务。元数据和目录均按照固定大小的条带存储,通过handle hash来定位存储位置(类似ext4)。文件系统的目录可能跨条带(对于大目录),跨mds 的rename 操作需要分布式锁保护,性能较低。
oss 对象存储作为数据存储, 每个oss object代表一个文件, object内部也是固定大小的条带化存储。Lustre的object 支持随机读写,object内部的条带像是块存储的条带,支持随机读写。
CephFS
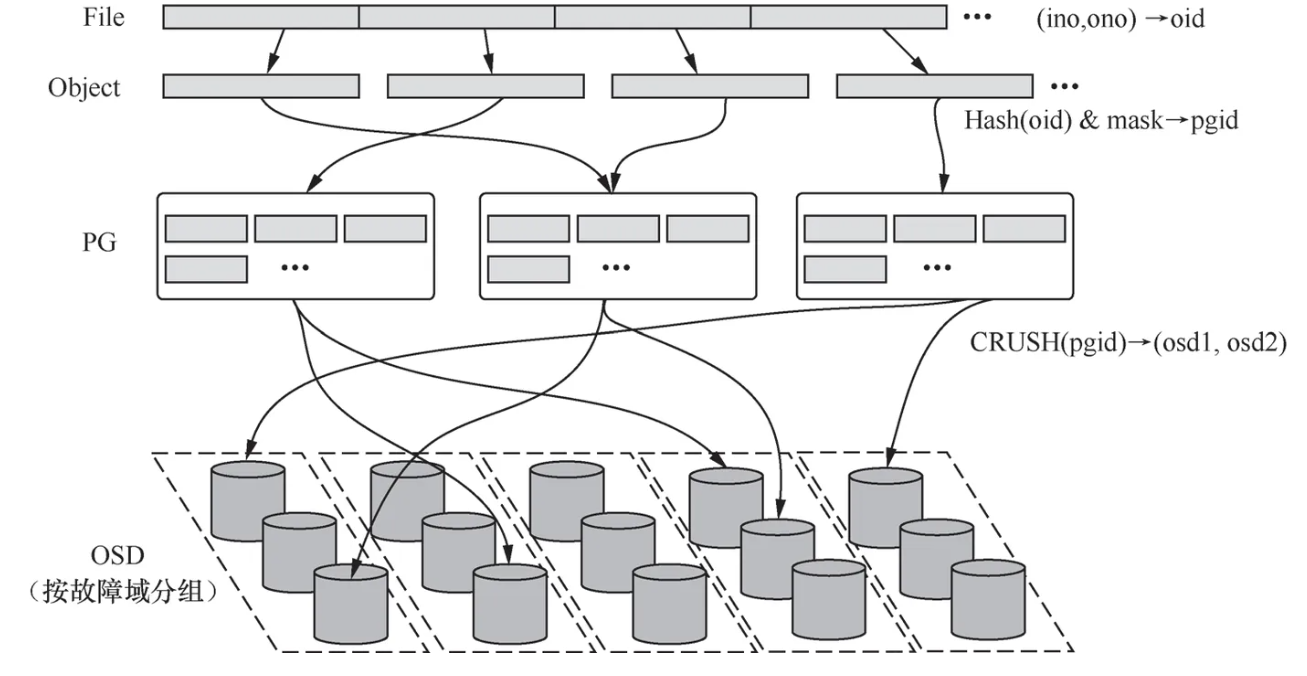
Ceph 发布于2006年,底层是RADOS(Reliable Autonomic Distributed Object Store)对象存储系统,这个对象同样是可以随机读写的(实际是条带)
RADOS 是具有负载均衡、容错的分布式存储服务,组成
- OSD(Object Storage Daemon)具体存放数据的存储节点
- PG(Placement Group)负责维护对象到OSD的映射,以及基于映射的负载均衡
元数据服务MDS,
- MDS 将目录树拆分为多个子树,分配给不同 MDS 实例管理。会根据子树的访问热度执行动态调度
- MDS 在内存态存放每个子树目录的目录项,文件元数据。持久化时还是以键值对形式存储在目录的 RADOS 对象中。对于MDS的操作会先通过日志持久化到 RADOS
官方文档,https://docs.ceph.com/en/latest/architecture/
GPFS
IBM 商业文件系统,闭源。
节点角色
- NSD(Network Shared Disk) Server, 管理物理存储设备(如磁盘阵列、SAN),将本地磁盘抽象为逻辑 NSD(Network Shared Disk), 负责数据容错,存储节点。文件被分割为固定大小的块(默认 256KB~16MB),分布到多个 NSD 上。
- Manager Node, 文件系统管理器(File System Manager),负责元数据操作(如目录结构、文件锁)以及颁发token用来协调客户端。同时通过仲裁节点(Quorum Node)实现高可用,通常部署奇数个节点(如 3 个)。Manager Node是无状态的, 元数据(inode、目录项)集中存储于专用 NSD。
- Client Node。挂载 GPFS 文件系统的计算节点,直接读写数据。客户端通过向Manager Node申请令牌(Token)协调并发访问,避免冲突和减少锁的使用(例如如果只有一个客户端执文件创建,那目录NSD的写入操作不需要分布式锁)
令牌是一种lease,客户端需向Manager Node申请令牌,获得权限后方可操作。令牌类型包括
- 元数据锁, 控制目录结构修改(如重命名、删除)。
- 数据锁, 协调文件块的读写冲突(如并发写入同一区域)。
客户端节点缓存元数据(如目录项、文件属性),减少对Manager Node的频繁访问, 其他客户端的修改会触发缓存失效。
在高性能分布式系统中,通过lease协调的读写减少分布式锁的使用
- 避免多写只允许一个节点写
- 每个客户端节点都有缓存,写完的节点通知其他节点更新缓存
这种客户端/服务端协调的读写架构,性能远比允许客户端随便发读写请求、通过加锁保证一致性的性能高。
gpfs文档,https://www.ibm.com/docs/en/storage-scale/5.2.1?topic=overview-gpfs-architecture
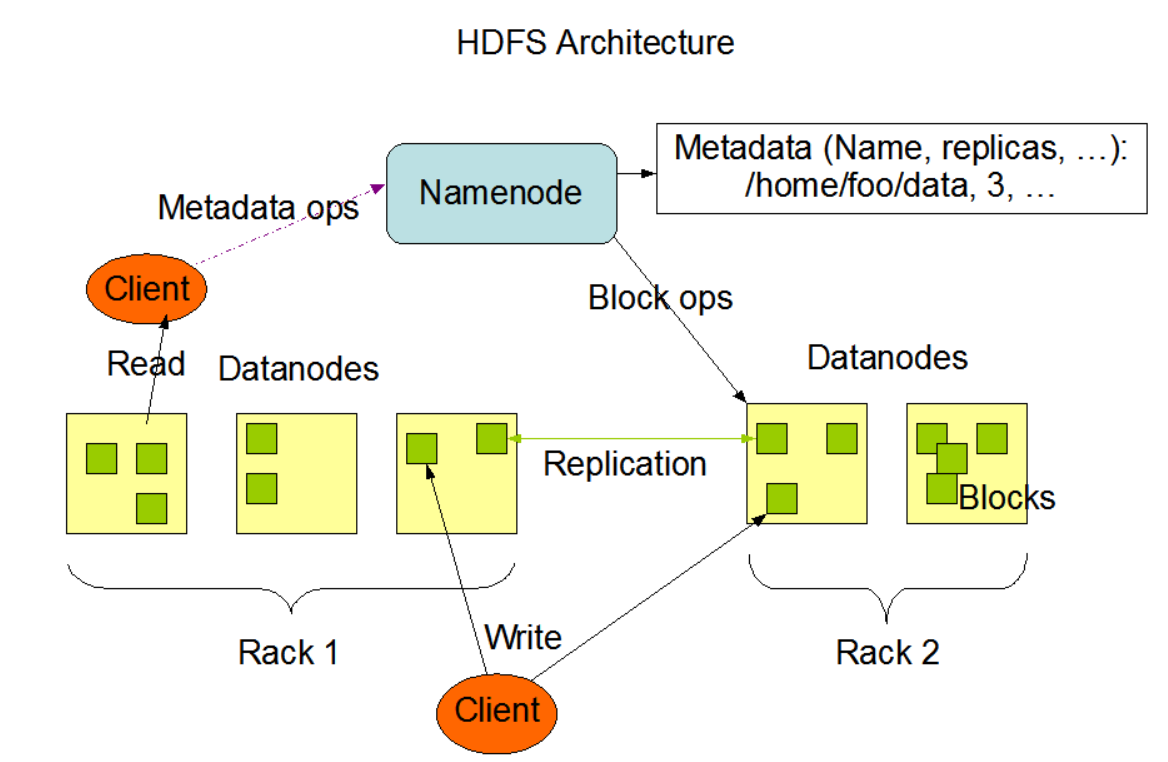
HDFS
不支持posix 语义, 设计目录是作为大数据分析中的存储系统,是GFS 的一种实现。
结构比较简单
- 使用NameNode 管理元数据,同时维护数据块物理信息,元数据不可水平扩展
- DataNode 存储数据,数据块可以水平扩展
- Client,元数据操作访问NameNode, 数据操作访问DataNode按需更新NameNode
NameNode 是性能和容量瓶颈, 并且由于hdfs是JAVA 开发, 一般用来配合Hbase 等hadoop全家桶用于大数据领域。
JuiceFS
支持posix 语义, 数据存储在对象存储(如 S3、OSS),元数据支持 Redis/MySQL/TiDB等一系列数据库作为元数据存储引擎, 借助TiDB 等分布式数据库提供了元数据的可扩展性。客户端借助fuse提供 操作系统接口。
- 最主要的优点是数据存储直接和S3对接,利用对象存储无限容量和底成本存储优势
- 本地内存和磁盘缓存加速元数据和数据性能。元数据可能是性能瓶颈,但付费版支持高性能元数据引擎
分布式数据库的数据表可以横向扩展(一般以partition为单位),文件系统的元数据就是若干数据表(KV表),因此自然提供了元数据扩展性。但通用的分布式KV引擎的readdir, rename 性能可能不高,需要针对优化。因此得到文件系统元数据对分布式KV存储的要求
- 单点查询性能高
- 范围查询(对应readdir)性能高
- 支持事务, 删除旧key+增加新key的性能高(对应rename)
- partition 拆分合理, 同一文件系统的若干partition 分布在距离近的机器, 需要有针对优化
JuiceFS架构文档, https://juicefs.com/docs/zh/community/architecture/
3FS
3FS (Fire-Flyer File System) 是一款高性能的分布式文件系统, 由 DeepSeek 在 2025 年 2 月开源。
- 3FS 的元数据以表的形式存在foundationDB服务中,操作元数据时,请求先发给元数据服务处理,然后发送到foundationDB。foundationDB以事务的形式写元数据,Read-only transactions used for metadata queries: fstat, lookup, listdir etc. Read-write transactions used for metadata updates: create, link, unlink, rename etc.
- storage service用户存储数据,数据被划分成等大的块(chunk, 条带),每三个块组成一条复制链(链式写入三副本保证容错性),以chain为单位打散storage server。文件到数据块的layout信息存在元数据服务中。storage server使用rocksdb维护自己的元数据信息(例如可用的块列表,块的分配情况等)。
- 提供FUSE 客户端和用户态客户端USRBIO(绕过内核和ring零拷贝),客户端会尽可能缓存文件的layout信息(文件chunk的分布情况),read/write请求客户端直接访问storage server。
- 客户端,meta server,storage server两两之间均使用RDMA通信。
3FS文档, https://github.com/deepseek-ai/3FS/blob/main/docs/design_notes.md
总结
对象存储,无目录结构,数据和元数据水平扩展简单,性能高,适合作为基础存储服务。
块存储,整个块设备可以认为是一个文件。支持随机读写和设备大小水平拓展。块设备需要极低延迟,块设备上可以格式化Ext4等单机文件系统。
支持分布式元数据的文件系统GlusterFS、CephFS、GPFS、JuiceFS、3FS; Lustre和HDFS不支持
使用块来存储目录项的文件系统, Ext4、GlusterFS、Lustre、CephFS、GPFS;使用KV 引擎存储目录项的文件系统, JuiceFS和3FS。在kv存储中,readdir 等于key的范围查询, rename等操作需要支持事务, 通过数据表水平拆分实现分布式元数据。
通过lease 来减少分布式锁的文件系统, GPFS。
- Ext4。单机文件系统,posix语义, 数据元数据按照块组织, 元数据和layout常驻内存。元数据和数据无法扩展
- GlusterFS。Brick 是组织数据和元数据基本单位,代表文件系统的一个目录(即按照目录拆分)。客户端的操作首先根据fsname和文件名定位到Brick,跨Brick的操作性能低。数据和元数据操作可能相互影响。
- Lustre。条带化对象存储作为数据存储,MDS负责管理元数据,元数据和目录项存到MDS本地,无元数据扩展能力。采用专用硬件(高速网络、低延迟存储), 适用于高性能存储。
- CephFS。底层使用对象存储RADOS提供可扩展性和容错性,MDS 将目录树按子树拆分,MDS是无状态的,目录项和元数据内容同样持久化到RADOS中。为通用存储设计。
- GPFS。NSD 负责数据存储,Manager Node管理元数据,元数据同样存储到NSD。客户端通过申请不同粒度的令牌在实现一致性的同时减少锁冲突。
- HDFS。非posix语义,NameNode 管理元数据, 元数据不可水平扩展,为大数据分析设计。
- JuiceFS可直接用S3 存储数据, KV和OLTP数据库管理元数据。利用本地内存和磁盘缓存加速元数据和数据性能。
- 3FS适用于高性能存储, 网络通信采用RDMA,元数据使用foundationDB, 数据使用链式块组织。
此外,基于paxos协议实现的zookeeper, etcd也是一种分布式文件系统, 提供高可用。但其只对外提供元数据服务,不适合存储大规模数据。常用的使用方式是1. 通过创建文件和lease 对外提供分布式锁 2. 以KV的形式存储少量重要数据,例如配置文件
以上,分布式文件系统建议基于CephFS和3FS建设,CephFS是通用文件系统,3FS侧重于高性能计算领域。优先考虑使用分布式KV作为元数据引擎。
by the way
我曾统计过我接触到的阿里云内部基础服务的开源替代性,发现最难以替代的是盘古分布式文件系统(其次是夸父高性能网络)。高性能,高可用,低成本的分布式文件系统毫无疑问是各大公司的核心科技。开源存储系统方便使用且满足高性能需求的很少,且相比于以上简要的架构,分布式存储系统的优化更重要。主要的优化点可能是
- 客户端和服务端联合优化,包括实现缓存减少后端访问,前后端流控,零拷贝,避免一方空转
- 分布式元数据。paxos协议高可用, 元数据尽可能内存化(通过压缩等手段存内存,性能比从磁盘读好很多),减少分布式锁导致性能下降,增强元数据可扩展性。元数据自动根据load调度
- 存储层提高IO性能,保证数据安全,降低存储成本,以及坏盘检测等优化
- 网络通信,通过用户态网络、rdma等技术,降低传输延迟
最后推荐三篇阿里云的论文
- 盘古存储 More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba. 链接 https://www.usenix.org/system/files/fast23-li-qiang_more.pdf
- 夸父网络 From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud. 链接 https://rmiao.github.io/assets/pdf/solar-sigcomm22.pdf
- 分布式KV引擎ArkDB ArkDB A Key-Value Engine for Scalable Cloud Storage Services 链接 https://dl.acm.org/doi/10.1145/3448016.3457553 这个链接无法下载论文,可以看 https://zhuanlan.zhihu.com/p/414054332
本文标题:存储——谈存储文件系统
文章作者:Infinity
发布时间:2025-04-07
最后更新:2025-04-29
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!