linux系统(3)——系统监控和问题排查
本文介绍linux系统的监控工具和问题排查的一般步骤,文章大体内容
- 用户程序一定要丰富trace和日志,并对trace做监控。正常情况下如果程序处理出现问题,会在监控告警中显示,介入排查可以通过trace和日志,判断出问题的文件、执行的线程等信息,绝大多数排查可以在这里停止,根本不用抓栈抓core。trace和日志必须包含的, 1. 时间戳 2. 函数名和位置 3. 线程ID和线程名, 这三个信息是排查必须
- 如果日志无法给出运行错误的原因,则需要进入机器查看。首先看有无core产生,产生core的原因一般是非法内存访问、double free、内存踩坏等或oom,因此首先去/var/log/messages 看是否oom导致,oom会记录到/var/log/messages日志。
- 如果没有core产生,但进程处理慢。可以先perf top -K -t $tid 查看耗时长的函数,原因大概是1. 被流控 2. 底层数据库/IO服务处理慢,反压上层 4. CPU/IO/网络被打满,资源不足 5. 线程数量不足,任务队列堆积 等原因,这些原因本都应该展示在监控和日志里
- 如果有oom,需要内存占用高的线程抓core,分析内存占用高和是否有内存泄漏;如果有core, 则需要分析产生core产生的原因。先在debug 环境下尝试复现core,同时调用valgrind等工具分析。分析core比较困难,可以直接找最有经验的人来协助。
系统CPU、内存、IO、网络监控
CPU和内存监控——top工具
top 能整体查看系统运行情况工具。利用top,能够观察到cpu,内存的运行情况,过滤出cpu 内存占用高的进程
1 | top - 16:16:56 up 16:55, 0 users, load average: 2.01, 1.83, 1.48 |
top -p $pid,输出指定进程的cpu使用情况; top -H -p $pid,输出指定进程的线程cpu使用情况
top 命令点击大写P、M实现按照cpu/mem 排序的进程,点击数字键1 可以看到每个cpu的占用。
IO监控——iostat
iostat是监控磁盘性能的工具。如果top发现cpu慢在wa,可以使用iostat看具体盘有无问题。命令iostat -x 1 2
1 | avg-cpu: %user %nice %system %iowait %steal %idle |
磁盘利用率表示io时间占cpu总时间的比例, 表示cpu处理空闲阶段且存在io操作,这段cpu时间片就认为是iowait消耗的
网络监控——ifconfig, netstat, ittop
ifconfig,查看网卡、ip地址、网络传输量、丢包情况等基本信息
1 | ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 |
netstat -nultp 查看pid和监听的端口信息, 可以用来查看链接数量
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
netstat -an | grep “:80” | wc -l, 查看端口的链接数量
netstat -r 显示路由表
netstat -s查看网络统计信息,统计时间是从系统启动到执行命令。如果想查最近1分钟的数据, 需要1分钟后再执行,二者数值作差
1 | Ip: |
sar和tsar 统计历史信息
以上top, netsta, iostat等工具只能统计当前时刻的信息,有时候我们需要历史统计信息,就需要sar和tsar
sar (System Activity Report) 是 Linux 系统中的一个性能监控工具,可以用来统计历史的cpu, 内存, io**, 网络等监控数据; tsar 是淘宝开源的性能监控工具, 同样可以用来统计历史监控数据。sar 需要安装sysstat
sar -u 1 5 统计cpu 信息
1 | 02:17:10 PM CPU %user %nice %system %iowait %steal %idle |
sar -hr 1 5 显示内存信息
1 | 02:18:34 PM kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty |
sar -d 1 5 查看磁盘统计, 统计每个磁盘的iops, 读写吞吐, wait, 使用率
1 | Average: DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util |
sar -n DEV 1 5 统计网络流量
1 | 02:35:32 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil |
sar -q 1 5 查看系统负载(进程数量)信息
1 | 02:35:51 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked |
进程监控
进程基本信息获取
ps -ef, ps aux 获得进程的pid, 状态等信息。一般拿到进程pid后就直接top -p
/proc/{pid} 目录可以看到进程相关资源信息。例如
/proc/{pid}/fd 查看打开的文件信息
1 | dr-x------ 2 root root 0 1月 3 23:22 ./ |
/proc/{pid}/cgroup,查看进程cgroup配置信息
1 | 13:hugetlb:/ |
具体的cgroup内容在/sys/fs/cgroup/下查看
1 | root@ubuntu2204:/home/tech-blog# ls /sys/fs/cgroup/ |
进程CPU内存IO使用情况
使用top -p $pid 可以查看进程的cpu/内存使用情况
pidstat 命令可以查看进程级的统计信息
基础信息统计
1 | root@ubuntu2204:/home/tech-blog# pidstat 1 5 |
进程性能问题排查
进程出现性能问题,原因可能如下
- CPU 资源不足,原因可能是进程cgroup限制cpu核数导致资源不足,CPU各核心负载分配不均,进程下线程数量过多,导致有的线程抢占不到CPUhang住等。CPU资源不足导致的结果一般是进程处理能力无法上升
- 内存资源不足,可能是发生内存踩坏、double free 或内存泄漏;前者导致进程崩溃产生core,后者导致进程内存使用不断上涨,直到oom被系统kill。
- IO资源不足,也就是读写数据库/文件变慢,这个最好排查
- 程序自身的问题,例如线程分配数量过少、存在函数耗时过长、死锁等导致性能问题
一般来说问题排查可以1-2-3-4逐次进行
CPU问题
CPU问题主要有两个1. CPU资源不足 2. CPU负载不均,某线程占用的大量CPU导致其他线程hang住
首先通过top看进程当前的cpu占用,看是否接近cgroup 的cpu核数限制
- 如果接近cgroup限制,适当调高cgroup
- 利用top查看所有的cpu核心是否打满,如果没有打满,后续应优化核心的资源均衡
- 利用top -p $pid -H查看cpu占用最高的线程
- 对cpu占用最高的线程执行,
perf top -K -t <tid>可以查看线程主要开销的调用栈,其中-K表示过滤调内核模块
perf top -K -t $tid的示例,注意线上千万不要对进程执行perf!!!否则有进程重启的风险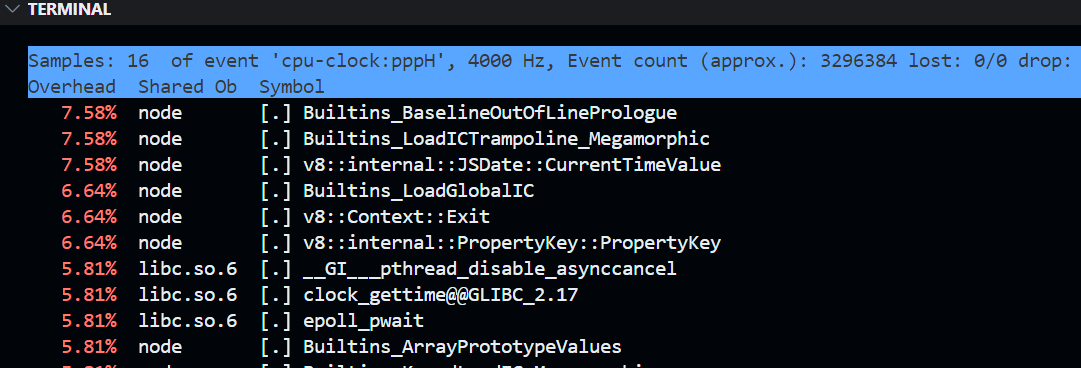
进一步的, 对线程抓热度图。命令如下
sudo perf record -e cpu-clock -t $tid --call-graph dwarf,如果要对进程执行,将-t $tid改为-p $pid, 执行完后会生成perf.data文件- 用perf script工具对perf.data文件解析,
perf script -i perf.data &> perf.unfold - 将perf.unfold中的符号折叠, 执行
./stackcollapse-perf.pl perf.unfold &> perf.folded - 最后生成svg火焰图
./flamegraph.pl perf.folded > perf.svg
其中./stackcollapse-perf.pl和./flamegraph.pl 工具均来自 https://github.com/brendangregg/FlameGraph
利用火焰图可以直观的观察调用栈和每个栈的执行时间,调用栈越宽的表示CPU执行时间长,可能需要优化。例如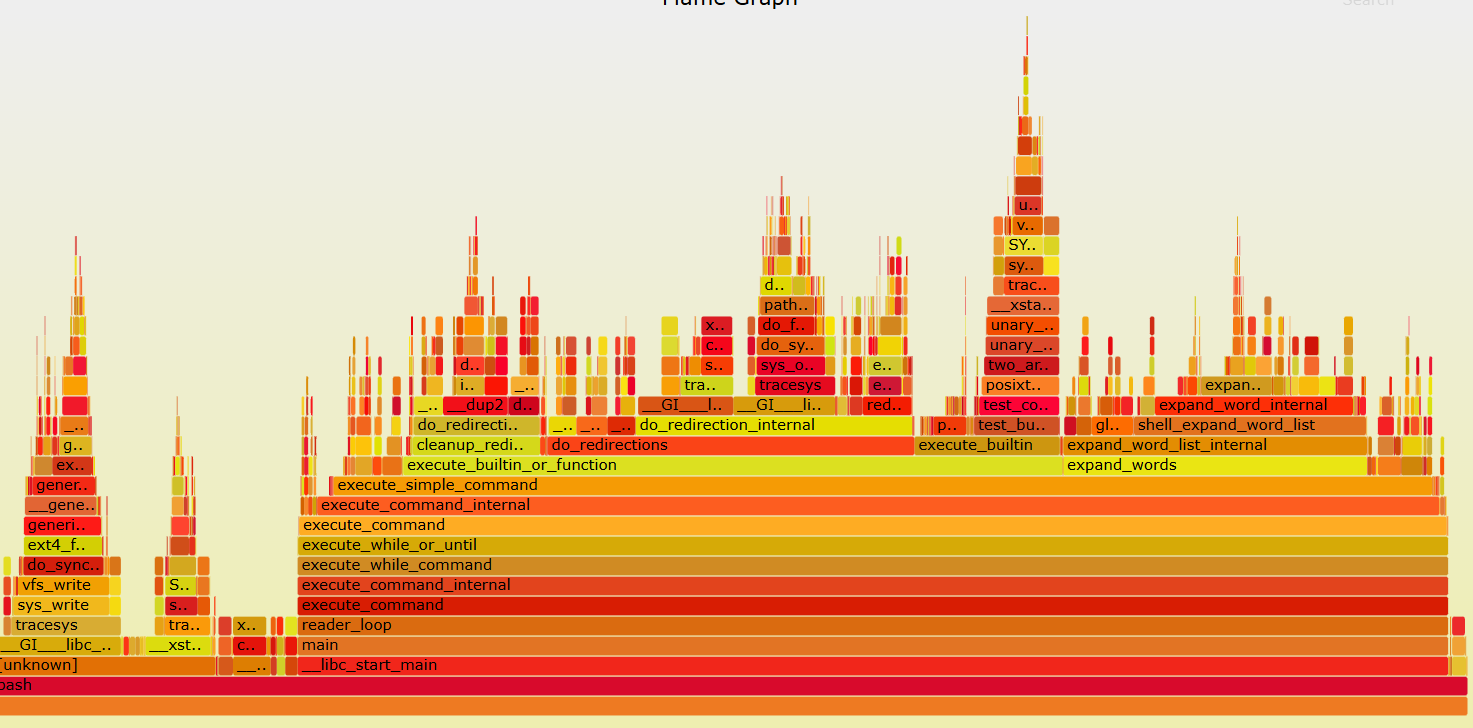
获取调用栈需要设置–call-graph dwarf, 参考 https://gaomf.cn/2019/10/30/perf_stack_traceback/
一般来说如果不是cgroup的问题,只能将进程的一些次要任务迁移走或调低,优先保证主要任务的CPU占用。
内存问题
内存问题也主要有两个1. 内存踩坏或double free(常发生在C/C++)2. 内存泄漏导致oom(也常发送在C/C++)。对于有GC的语言如JAVA、GO,如果内存用量持续增高,只要观察并调整相应jvm参数加快GC,就可缓解内存上涨;而对于C/C++,由于内存创建和释放完全由程序员负责,内存泄漏问题很常见,且难以排查。
C++ 的debug编译一定开启asan(Address Sanitizer), 即g++ -fsanitize=address -g xxx, 在UT覆盖的情况下执行UT 时Asan可以帮助检查内存泄漏。其核心原理是通过 内存插桩(Instrumentation) 和 影子内存(Shadow Memory) 机制,实时监控程序的内存操作。Valgrind 也用于内存泄漏的工具,相比asan是编译期插桩,Valgrind是运行期插桩,运行慢但检查更全面。一般选择asan快速定位内存问题,再用Valgrind深入分析。
Asan和Valgrind都会带来性能损失,一般只用于debug 环境。
如果生成环境遇到内存踩坏或内存泄漏,前者一般导致进程产生core,后者在监控上能看到机器内存使用一直缓慢增长。这时我们一般首先拿到core文件,内存踩坏一般直接会产生core,内存泄漏我们使用gcore来抓core, gcore抓core可能要持续几十秒(请耐心等待)。gcore命令的好处是不需要进程重启。(执行kill -s 11会让进程直接segment fault产生core,但会导致进程重启)。如果是内存泄漏问题,可以先尝试对内存占用高的线程进行抓core
一个优化的抓core方法是让进程提供抓core的运维命令,进程收到命令后,fork出一个子进程继续处理任务,将父进程abort()掉,自动生成core。
抓到core后可以获取两种信息
- 进程core掉时的每个线程的调用栈信息
- 进程core掉时的内存信息
获取线程调用栈信息的步骤, 执行如下命令将所有调用栈打印到gdb.txt文件中
1 | gdb binary corefile |
获取进程core掉的内存信息,
- gdb里执行
info proc mappings命令显示core文件中的虚拟内存映射表,同时会输出每个内存映射的start_addr, end_addr, size, offset, objfile - 执行
dump binary memory result.bin $start_addr $end_addr将内存大隐刀本地result.bin文件中 - 在vim里查看result.bin文件,通过
:%!xxd方式以16进制模式来查看,左侧是16进制地址,右侧是ASCII字符
主要是看右侧的ASCII字符,看有没有相关的提示。
C++ 的release binary和core 会丢失代码里的类型信息、函数信息,core能看到的大多数只是一串内存地址和内存里的数据,但我们难以知道这段内存对应代码的哪个地方。一方面我们要猜测哪个地址发生了内存泄漏,另一方面也要猜测发生内存泄漏的地址位于哪部分代码。
我们可以通过强化tcmalloc和gdb工具辅助排查内存泄漏,tcmalloc主要是插桩,在tcmalloc分配和释放内存时做记录,gdb主要是辅助解析,例如统计申请内存大小为xxx的调用信息。利用这些记录和统计信息可以帮助内存泄漏的排查。如果C++程序里有虚函数,也可以通过虚函数记录的类型信息帮助分析(JAVA的函数默认都是虚函数,这让JAVA排查core比C++简单很多)。
IO和程序自身的问题
如果是程序自身的问题,1. 导致CPU占用高 2. 导致内存踩坏或内存泄漏,前面已经分析过
用户程序必须要打印trace日志,尤其是读写文件、读写数据库等IO操作,通过trace日志可以直接判断IO问题。
用户程序应该要让线程定期执行报备的操作,如果某个线程长期没有报备,则说明该线程要么Hang住,要么死锁,要么是其他原因阻塞住。
pstack和strace
sudo pstack $pid 用来抓进程/线程调用栈
strace -p $pid, 用来抓进程/线程的系统调用信息
这两个命令都十分有用,可以在发现CPU、内存、IO的异常线程时,对线程执行sudo pstack 和sudo strace, 但切记不要对进程执行这俩命令。
如果是线程死锁导致进程处理慢,pstack几次线程就可以判断死锁了。
总结
debug环境下要做到
- 编译开启asan检查内存泄漏,有必要的话clang-format, clang-tidy, Valgrind 也要打开
- UT覆盖率至少90%,UT可以保证单线程场景下接口的运行正确,无内存泄漏
- 上线前一定要进行多并发压测和长稳测试,主要是观察多线程情况下程序运行是否正常
- 上线前的功能测试,目的是确认程序功能正常,也就是程序逻辑是对的。如果程序逻辑不正确,上线后难以检测到(无法通过CPU,内存,QPS等指标判断异常)。**因此功能覆盖率一定要100%**。
用户程序一定要丰富trace和日志,并对trace做监控。正常情况下如果程序处理出现问题,会在监控告警中显示,介入排查可以通过trace和日志,判断出问题的文件、执行的线程等信息,绝大多数排查可以在这里停止,根本不用抓栈抓core。trace和日志必须包含的, 1. 时间戳 2. 函数名和位置 3. 线程ID和线程名, 这三个信息是排查必须
如果日志无法给出运行错误的原因,则需要进入机器查看
- 首先看有无core产生,产生core的原因一般是非法内存访问、double free、内存踩坏等或oom,因此首先去/var/log/messages 看是否oom导致,oom会记录到/var/log/messages日志。
1
2kernel: Out of memory: Kill process 12345 (java) score 678 or sacrifice child
kernel: Killed process 12345 (java) total-vm:123456kB, anon-rss:65432kB, file-rss:0kB, shmem-rss:0kB
如果没有core产生,但进程处理慢。可以先perf top -K -t $tid 查看耗时长的函数,原因大概是1. 被流控 2. 底层数据库/IO服务处理慢,反压上层 4. CPU/IO/网络被打满,资源不足 5. 线程数量不足,任务队列堆积 等原因,这些原因本都应该展示在监控和日志里
如果有oom,需要内存占用高的线程抓core,分析内存占用高和是否有内存泄漏
如果有core, 则需要分析产生core产生的原因。先在debug 环境下尝试复现core,同时调用valgrind等工具分析。分析core比较困难,可以直接找最有经验的人来协助。
可以借助大量的问题排查分享来积累经验,例如 https://www.cnblogs.com/xingmuxin/p/11287935.html
linux系统日志
linux 系统日志,默认存储在/var/log目录下
1 | /var/log/ |
nginx, mysql 等系统服务可能把日志写到/var/log下
/var/log/nginx/access.log Nginx 访问日志(客户端请求) tail -f /var/log/nginx/access.log
/var/log/mysql/error.log MySQL 错误日志 sudo less /var/log/mysql/error.log
journalctl:查看 systemd 日志(支持服务筛选、时间范围)
1 | journalctl -u nginx.service -f # 实时追踪 Nginx 日志 |
dmesg:查看内核环形缓冲区日志。内核环形缓冲区(Kernel Ring Buffer)是Linux内核用于临时存储运行时消息(如硬件事件、驱动状态、系统错误)的内存区域。
1 | dmesg | grep "USB" # 检查 USB 设备事件 |
配置日志轮转
/etc/logrotate.conf 和 /etc/logrotate.d/*
本文标题:linux系统(3)——系统监控和问题排查
文章作者:Infinity
发布时间:2024-12-05
最后更新:2025-07-06
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!